Natural language processing opened the door for semantic search on Google.
SEOs need to understand the switch to entity-based search because this is the future of Google search.
In this article, we’ll dive deep into natural language processing and how Google uses it to interpret search queries and content, entity mining, and more.
What is natural language processing?
Natural language processing, or NLP, makes it possible to understand the meaning of words, sentences and texts to generate information, knowledge or new text.
It consists of natural language understanding (NLU) – which allows semantic interpretation of text and natural language – and natural language generation (NLG).
NLP can be used for:
Speech recognition (text to speech and speech to text).Segmenting previously captured speech into individual words, sentences and phrases.Recognizing basic forms of words and acquisition of grammatical information.Recognizing functions of individual words in a sentence (subject, verb, object, article, etc.)Extracting the meaning of sentences and parts of sentences or phrases, such as adjective phrases (e.g., “too long”), prepositional phrases (e.g., “to the river”), or nominal phrases (e.g., “the long party”).Recognizing sentence contexts, sentence relationships, and entities.Linguistic text analysis, sentiment analysis, translations (including those for voice assistants), chatbots and underlying question and answer systems.
The following are the core components of NLP:
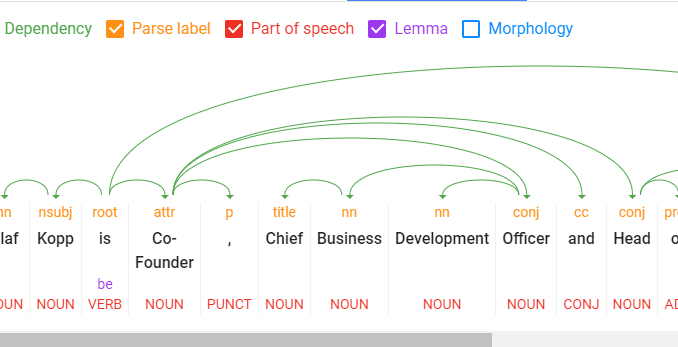
A look into Google’s Natural Language Processing API
Tokenization: Divides a sentence into different terms.Word type labeling: Classifies words by object, subject, predicate, adjective, etc.Word dependencies: Identifies relationships between words based on grammar rules. Lemmatization: Determines whether a word has different forms and normalizes variations to the base form. For example, the base form of “cars” is “car.”Parsing labels: Labels words based on the relationship between two words connected by a dependency.Named entity analysis and extraction: Identifies words with a “known” meaning and assigns them to classes of entity types. In general, named entities are organizations, people, products, places, and things (nouns). In a sentence, subjects and objects are to be identified as entities.
Entity analysis using the Google Natural Processing API.
Salience scoring: Determines how intensively a text is connected with a topic. Salience is generally determined by the co-citation of words on the web and the relationships between entities in databases such as Wikipedia and Freebase. Experienced SEOs know a similar method from TF-IDF analysis.Sentiment analysis: Identifies the opinion (view or attitude) expressed in a text about the entities or topics.Text categorization: At the macro level, NLP classifies text into content categories. Text categorization helps to determine generally what the text is about.Text classification and function: NLP can go further and determine the intended function or purpose of the content. This is very interesting to match a search intent with a document.Content type extraction: Based on structural patterns or context, a search engine can determine a text’s content type without structured data. The text’s HTML, formatting, and data type (date, location, URL, etc.) can identify whether it is a recipe, product, event or another content type without using markups.Identify implicit meaning based on structure: The formatting of a text can change its implied meaning. Headings, line breaks, lists and proximity convey a secondary understanding of the text. For example, when text is displayed in an HTML-sorted list or a series of headings with numbers in front of them, it is likely to be a listicle or a ranking. The structure is defined not only by HTML tags but also by visual font size/thickness and proximity during rendering.
The use of NLP in search
For years, Google has trained language models like BERT or MUM to interpret text, search queries, and even video and audio content. These models are fed via natural language processing.
Google search mainly uses natural language processing in the following areas:
Interpretation of search queries.Classification of subject and purpose of documents.Entity analysis in documents, search queries and social media posts.For generating featured snippets and answers in voice search.Interpretation of video and audio content.Expansion and improvement of the Knowledge Graph.
Google highlighted the importance of understanding natural language in search when they released the BERT update in October 2019.
“At its core, Search is about understanding language. It’s our job to figure out what you’re searching for and surface helpful information from the web, no matter how you spell or combine the words in your query. While we’ve continued to improve our language understanding capabilities over the years, we sometimes still don’t quite get it right, particularly with complex or conversational queries. In fact, that’s one of the reasons why people often use “keyword-ese,” typing strings of words that they think we’ll understand, but aren’t actually how they’d naturally ask a question.”
BERT & MUM: NLP for interpreting search queries and documents
BERT is said to be the most critical advancement in Google search in several years after RankBrain. Based on NLP, the update was designed to improve search query interpretation and initially impacted 10% of all search queries.
BERT plays a role not only in query interpretation but also in ranking and compiling featured snippets, as well as interpreting text questionnaires in documents.
“Well, by applying BERT models to both ranking and featured snippets in Search, we’re able to do a much better job helping you find useful information. In fact, when it comes to ranking results, BERT will help Search better understand one in 10 searches in the U.S. in English, and we’ll bring this to more languages and locales over time.”
The rollout of the MUM update was announced at Search On ’21. Also based on NLP, MUM is multilingual, answers complex search queries with multimodal data, and processes information from different media formats. In addition to text, MUM also understands images, video and audio files.
MUM combines several technologies to make Google searches even more semantic and context-based to improve the user experience.
With MUM, Google wants to answer complex search queries in different media formats to join the user along the customer journey.
As used for BERT and MUM, NLP is an essential step to a better semantic understanding and a more user-centric search engine.
Understanding search queries and content via entities marks the shift from “strings” to “things.” Google’s aim is to develop a semantic understanding of search queries and content.
By identifying entities in search queries, the meaning and search intent becomes clearer. The individual words of a search term no longer stand alone but are considered in the context of the entire search query.
The magic of interpreting search terms happens in query processing. The following steps are important here:
Identifying the thematic ontology in which the search query is located. If the thematic context is clear, Google can select a content corpus of text documents, videos and images as potentially suitable search results. This is particularly difficult with ambiguous search terms. Identifying entities and their meaning in the search term (named entity recognition).Understanding the semantic meaning of a search query.Identifying the search intent.Semantic annotation of the search query.Refining the search term.
Get the daily newsletter search marketers rely on.
Processing…Please wait.
SUBSCRIBE
See terms.
function getCookie(cname) {
let name = cname + “=”;
let decodedCookie = decodeURIComponent(document.cookie);
let ca = decodedCookie.split(‘;’);
for(let i = 0; i <ca.length; i++) {
let c = ca[i];
while (c.charAt(0) == ‘ ‘) {
c = c.substring(1);
}
if (c.indexOf(name) == 0) {
return c.substring(name.length, c.length);
}
}
return “”;
}
document.getElementById(‘munchkinCookieInline’).value = getCookie(‘_mkto_trk’);
NLP is the most crucial methodology for entity mining
Natural language processing will play the most important role for Google in identifying entities and their meanings, making it possible to extract knowledge from unstructured data.
On this basis, relationships between entities and the Knowledge Graph can then be created. Speech tagging partially helps with this.
Nouns are potential entities, and verbs often represent the relationship of the entities to each other. Adjectives describe the entity, and adverbs describe the relationship.
Example of NLP building a Knowledge Graph: Mining Knowledge Graphs from Text (WSDM 2018).
Google has so far only made minimal use of unstructured information to feed the Knowledge Graph.
It can be assumed that:
The entities recorded so far in the Knowledge Graph are only the tip of the iceberg.Google is additionally feeding another knowledge repository with information on long-tail entities.
NLP plays a central role in feeding this knowledge repository.
Google is already quite good in NLP but does not yet achieve satisfactory results in evaluating automatically extracted information regarding accuracy.
Data mining for a knowledge database like the Knowledge Graph from unstructured data like websites is complex.
In addition to the completeness of the information, correctness is essential. Nowadays, Google guarantees completeness at scale through NLP, but proving correctness and accuracy is difficult.
This is probably why Google is still acting cautiously regarding the direct positioning of information on long-tail entities in the SERPs.
Entity-based index vs. classic content-based index
The introduction of the Hummingbird update paved the way for semantic search. It also brought the Knowledge Graph – and thus, entities – into focus.
The Knowledge Graph is Google’s entity index. All attributes, documents and digital images such as profiles and domains are organized around the entity in an entity-based index.
The Knowledge Graph is currently used parallel to the classic Google Index for ranking.
Suppose Google recognizes in the search query that it is about an entity recorded in the Knowledge Graph. In that case, the information in both indexes is accessed, with the entity being the focus and all information and documents related to the entity also taken into account.
An interface or API is required between the classic Google Index and the Knowledge Graph, or another type of knowledge repository, to exchange information between the two indices.
This entity-content interface is about finding out:
Whether there are entities in a piece of content.Whether there is a main entity that the content is about.Which ontology or ontologies the main entity can be assigned to.Which author or which entity the content is assigned.How the entities in the content relate to each other.Which properties or attributes are to be assigned to the entities.
It could look like this:
We’re just starting to feel the impact of entity-based search in the SERPs as Google is slow to understand the meaning of individual entities.
Entities are understood top-down by social relevance. The most relevant ones are recorded in Wikidata and Wikipedia, respectively.
The big task will be to identify and verify long-tail entities. It is also unclear which criteria Google checks for including an entity in the Knowledge Graph.
In a German Webmaster Hangout in January 2019, Google’s John Mueller said they were working on a more straightforward way to create entities for everyone.
“I don’t think we have a clear answer. I think we have different algorithms that check something like that and then we use different criteria to pull the whole thing together, to pull it apart and to recognize which things are really separate entities, which are just variants or less separate entities… But as far as I’m concerned I’ve seen that, that’s something we’re working on to expand that a bit and I imagine it’ll make it easier to get featured in the Knowledge Graph as well. But I don’t know what the plans are exactly.”
NLP plays a vital role in scaling up this challenge.
Examples from the diffbot demo show how well NLP can be used for entity mining and constructing a Knowledge Graph.
NLP in Google search is here to stay
RankBrain was introduced to interpret search queries and terms via vector space analysis that had not previously been used in this way.
BERT and MUM use natural language processing to interpret search queries and documents.
In addition to the interpretation of search queries and content, MUM and BERT opened the door to allow a knowledge database such as the Knowledge Graph to grow at scale, thus advancing semantic search at Google.
The developments in Google Search through the core updates are also closely related to MUM and BERT, and ultimately, NLP and semantic search.
In the future, we will see more and more entity-based Google search results replacing classic phrase-based indexing and ranking.
The post How Google uses NLP to better understand search queries, content appeared first on Search Engine Land.
Source: Search Engine Land
Link: How Google uses NLP to better understand search queries, content
